Loading TuneTrain.ai...
Loading TuneTrain.ai...
Transform your data into powerful, customized language models. Augment your dataset, select a model, and deploy your fine-tuned AI easily.
Fine-tune from a curated selection of state-of-the-art small language models, optimized for efficiency and performance.
Professional AI model fine-tuning made simple and accessible for businesses of all sizes.
Easily upload, organize, and manage your datasets in CSV and JSONL formats. Track versions and maintain data quality.
Generate synthetic data variations and expand your datasets automatically to improve model performance and diversity.
Leverage large language models to distill knowledge into smaller, efficient models while maintaining quality.
Fine-tune models with instruction-following capabilities. Train AI to understand and execute specific tasks.
Coming soon: Train conversational AI with dialogue-specific fine-tuning for chatbots and assistants.
Coming soon: Deploy your fine-tuned models with our managed hosting, API endpoints, and scaling infrastructure.
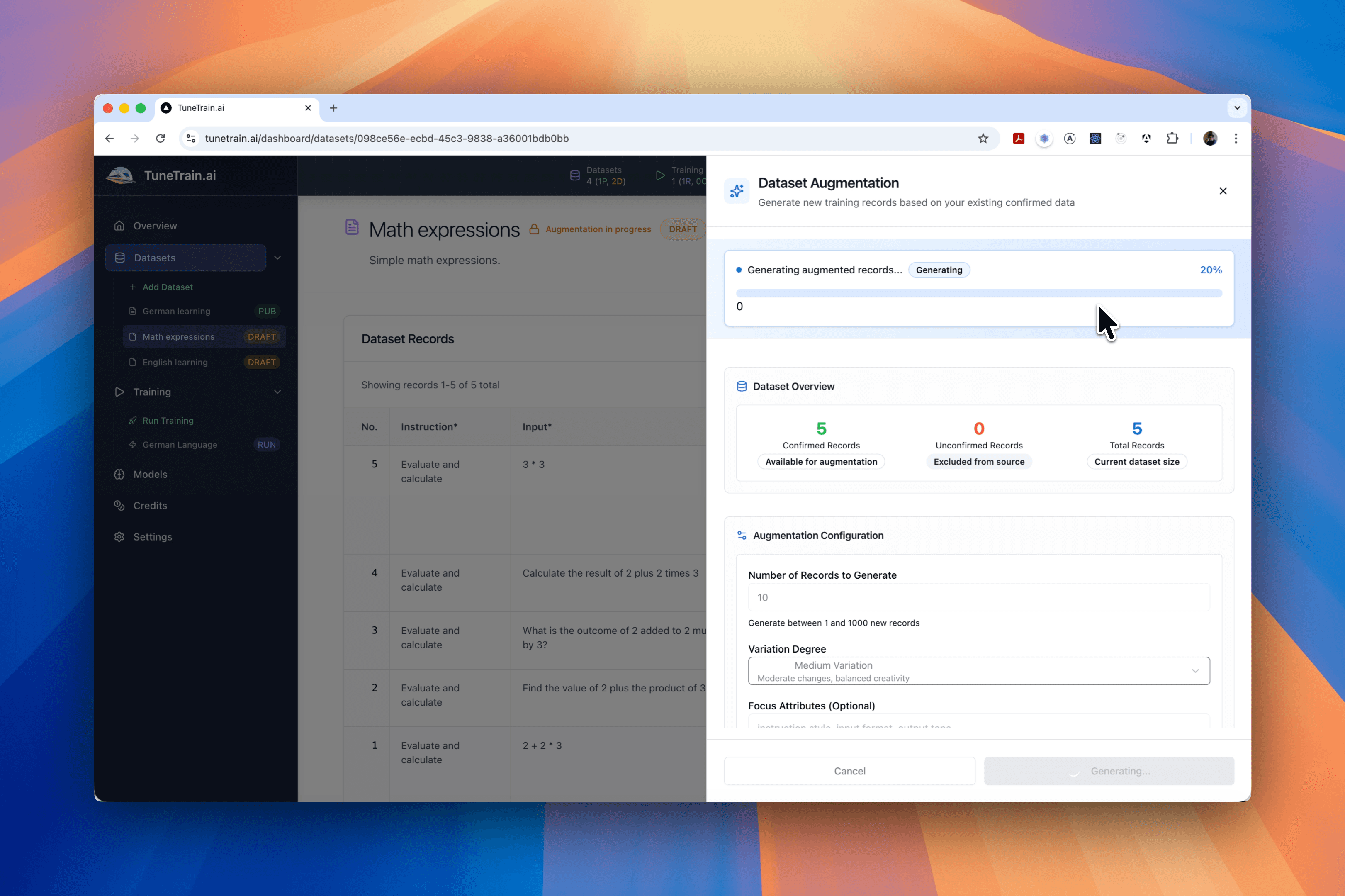
Enhance your datasets with our advanced augmentation tools. Generate synthetic data, expand existing datasets, and improve model performance with ease. Use LLMs to distill knowledge into your datasets, ensuring your models are trained on the most relevant and comprehensive information.
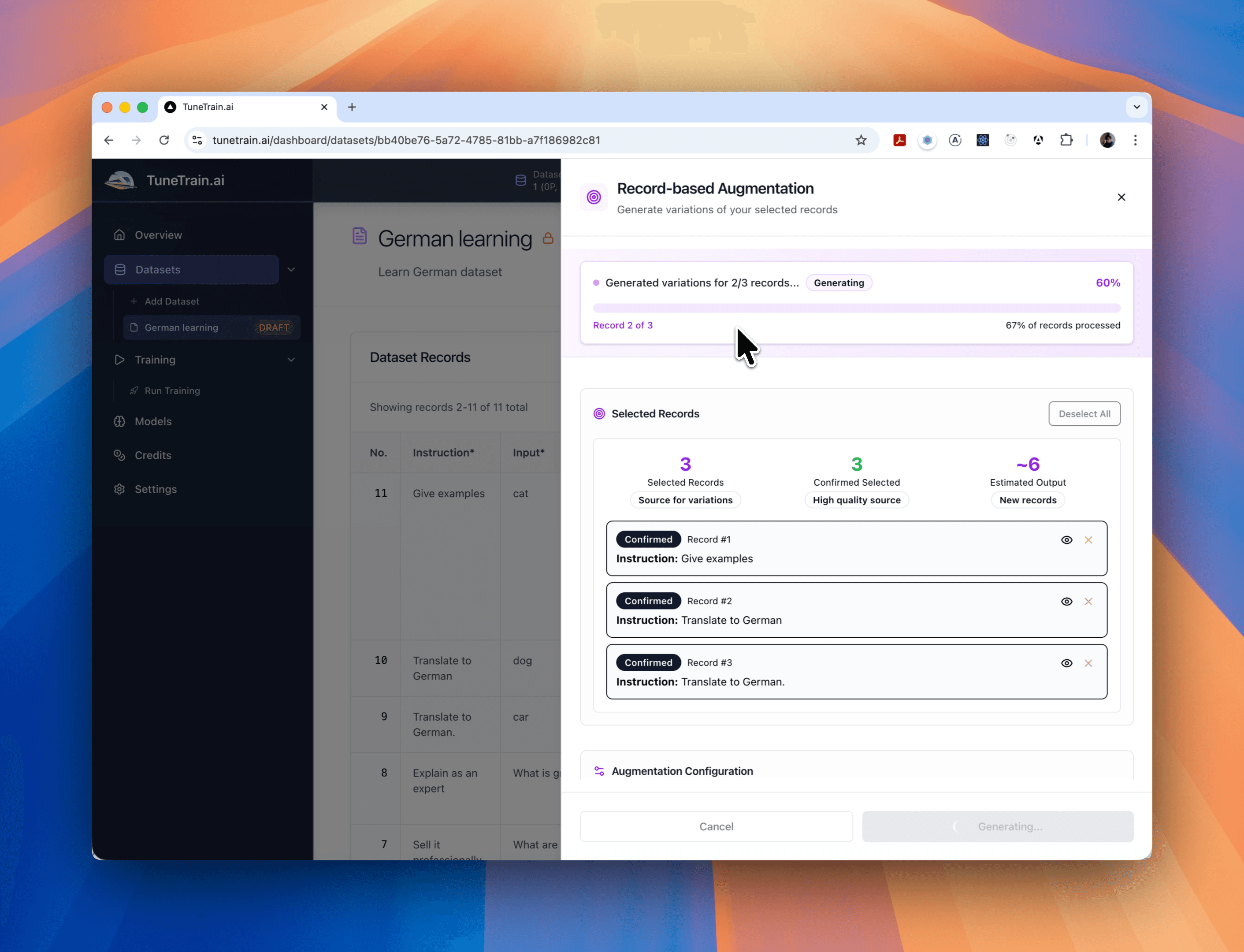
Easily expand your datasets by generating new records based on existing ones. Our record-based augmentation tools help you create diverse and comprehensive datasets, improving model accuracy and robustness.
Everything you need to fine-tune language models
Everything you need to know about fine-tuning language models with TuneTrain.ai. Can't find what you're looking for? Contact our support team.
TuneTrain.ai is a comprehensive platform for fine-tuning small language models. Manage your datasets, augment them with AI-powered tools, use LLM-based distillation to enhance quality, and fine-tune models like Llama 3, Mistral, and Phi-4. Our platform handles the complex training process, giving you customized models trained specifically on your data.
Dataset augmentation automatically generates synthetic data variations from your existing records, expanding your dataset and improving diversity. This helps your models learn better patterns and generalize more effectively, especially when you have limited training data. You can augment entire datasets or select specific records for targeted expansion.
LLM-based distillation uses large language models to enhance your training data by generating high-quality examples, refining existing records, and distilling knowledge into smaller, more efficient models. This allows you to leverage the capabilities of advanced LLMs while creating models that are faster and more cost-effective to run.
We support popular small language models including Llama 3, Mistral, Phi-4, Gemma, Qwen, and other cutting-edge architectures. Our platform focuses on efficient models that can be deployed on consumer hardware while maintaining high performance. The model library is regularly updated with the latest releases.
You can upload datasets in CSV and JSONL formats with instruction-input-output structure. Our platform provides dataset management tools for creating, editing, and organizing your training data. Published datasets can be cloned for versioning, and draft datasets can be freely edited before publishing.
Absolutely. Your data is encrypted and processed in secure environments. We're EU AI Act compliant and follow strict data protection standards including GDPR. Your datasets and models remain private to your account. Training data is never used to improve our platform or shared with third parties.
Yes, you retain full ownership of your fine-tuned models. Once training is complete, you can download the model files including weights, configuration, and tokenizer. The models are yours to use commercially without restrictions, and you can deploy them wherever you choose.
No technical background required! Our platform is designed for ease of use with intuitive dataset management, guided augmentation workflows, and automated training processes. However, understanding your use case and data structure helps achieve better results. We provide comprehensive guides and best practices.
We use a credit-based system where credits are consumed for dataset augmentation and model training based on computational resources and time. You only pay for what you use with transparent, upfront pricing. Each operation shows its cost before you start, and you can monitor your credit balance in real-time.
Currently, you can download your trained models for self-hosting and deployment. Model hosting and deployment features with managed API endpoints are coming soon, allowing you to deploy models directly from the platform with automatic scaling and monitoring.
Our team is here to help you get started with AI model fine-tuning.
Transform your data into powerful AI models. No ML expertise required.